I’ve seen around tons of confusion about Optimus laptops, Prime and systems with multiple GPUs (like a desktop with an Nvidia dedicated GPU and an embedded AMD GPU) and how to configure them. People get mad with variables, scripts and extra tools.
The truth is, there’s not much to configure and since a few years, for most common cases, everything works out of the box.
Let’s take into consideration a very common case, a laptop with Intel + Nvidia GPU (Dell Precision 5680, Nvidia Optimus):
$ lspci | grep -i vga
00:02.0 VGA compatible controller: Intel Corporation Raptor Lake-P [Iris Xe Graphics] (rev 04)
01:00.0 VGA compatible controller: NVIDIA Corporation AD104GLM [RTX 3500 Ada Generation Laptop GPU] (rev a1)
And then let’s take the two most common cases into consideration to drive the GPUs.
- Intel + Nouveau open source driver (DRI/DRI)
- Intel open source driver + Nvidia proprietary driver (DRI/NVIDIA)
Power management
The system boots with the graphical output driven by the integrated Intel GPU (00:02.0) and the Nvidia GPU (01:00.0) is off.
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
suspended
A simple command that touches the PCI card like lspci or nvidia-settings is enough to wake up the Nvidia GPU for probing:
$ lspci > /dev/null
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
active
A few seconds after, the GPU is again in suspended:
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
suspended
The transition is always fast if no program is using the GPU, it usually takes just 4 or 5 seconds for the GPU to turn off. For example after exiting a game, you hear immediately the fan shutting down when the GPU goes off.
This is the simplest way to check power state of the GPU both when using the open source Nouveau driver and the Nvidia proprietary driver.
VGA Switcheroo (DRM drivers only)
If you are using the open source driver, there are a few added benefits in terms of control. The VGA Switcheroo files appear as soon as two GPU drivers and one handler have registered with vga_switcheroo. since multiple GPUs are using a common framework, vga_switcheroo is enabled and we we can manipulate the state of the devices:
$ sudo cat /sys/kernel/debug/vgaswitcheroo/switch
0:IGD:+:Pwr:0000:00:02.0
1:DIS-Audio: :DynOff:0000:01:00.1
2:DIS: :DynOff:0000:01:00.0
After firing up the GPU for a workload, we can see the state reflected into the virtual file:
$ sudo cat /sys/kernel/debug/vgaswitcheroo/switch
0:IGD:+:Pwr:0000:00:02.0
1:DIS-Audio: :DynOff:0000:01:00.1
2:DIS: :DynPwr:0000:01:00.0
The DIS-Audio device is the actual HDA sound card on the GPU that is used to send output to an external output (ex. HDMI). That is also controlled by the dynamic control of the devices.
The configuration is flexible, so for example you could have two or more discrete GPUs and one extra audio controller for an eventual HDMI port.
You can also do some really lowlevel stuff, like this one to switch the display output to the discrete GPU if you have an old system with disconnected GPUs that uses a MUX to switch the display output:
$ sudo echo MDIS > /sys/kernel/debug/vgaswitcheroo/switch
Selecting the GPU to use when running a program from the desktop
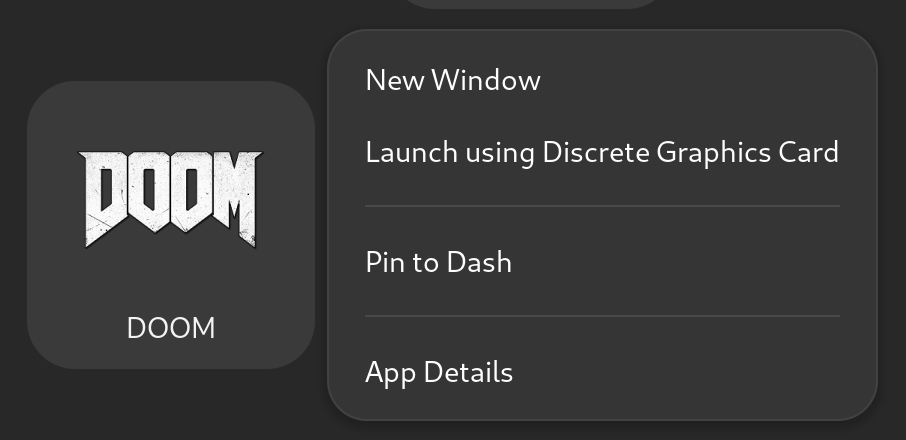
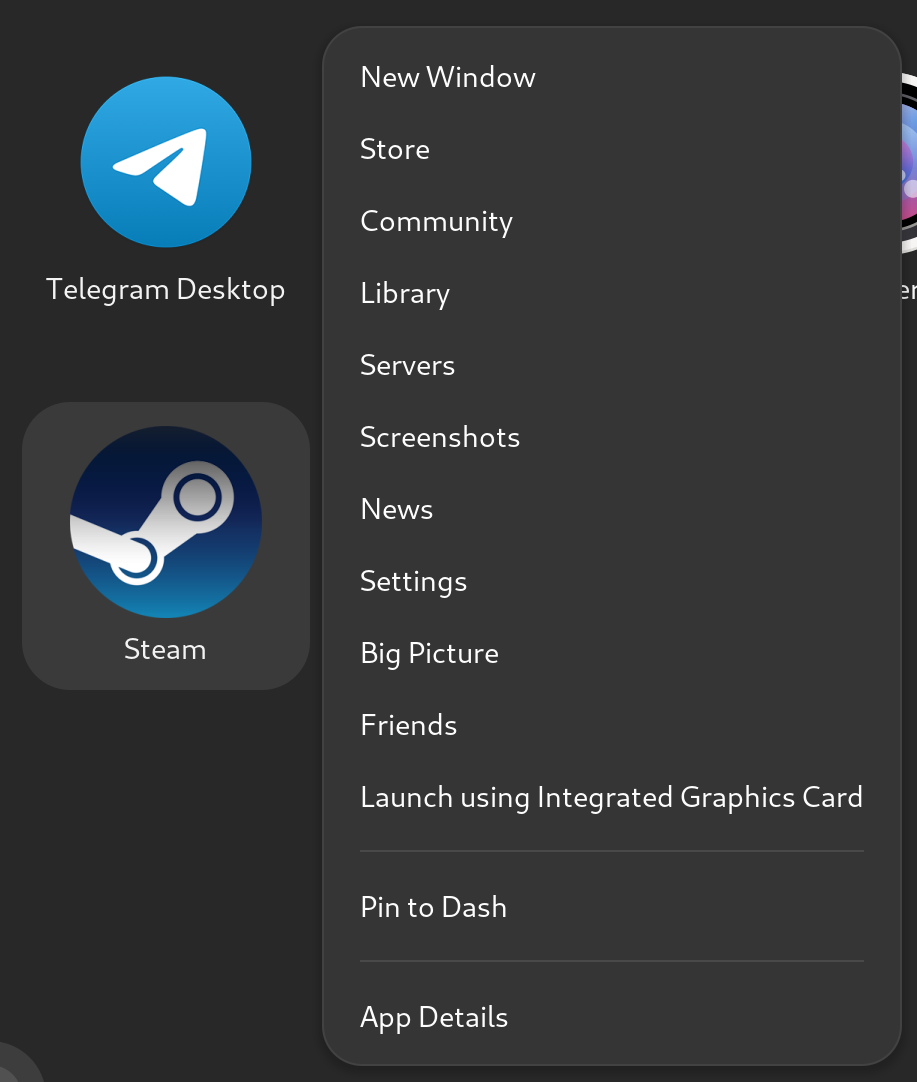
If running on Gnome or KDE, any application can be selected to run on the discrete GPU directly from the desktop by right clicking on the icon:
This is supported both in the case of multiple DRI/DRM devices and or a combination with Nvidia proprietary drivers. There is no visible difference between the two.
Both Gnome and KDE feature an extra setting that can be added to desktop menus to prefer the integrated GPU. For example Steam provides this by default:
$ cat /usr/share/applications/steam.desktop | grep -i GPU
PrefersNonDefaultGPU=true
X-KDE-RunOnDiscreteGpu=true
Applications bearing those entries receive the opposite treatment, they run by default on the discrete GPU and by right clicking we can select the internal GPU:
Selecting the GPU to use with switcherooctl
The system comes with a userspace utility to manipulate the GPUs and that also prints the variables you can use to address a specific GPU. Prime / VGA Swicheroo case:
$ switcherooctl list
Device: 0
Name: Intel Corporation Raptor Lake-P [Iris Xe Graphics]
Default: yes
Environment: DRI_PRIME=pci-0000_00_02_0
Device: 1
Name: NVIDIA Corporation AD104GLM [RTX 3500 Ada Generation Laptop GPU]
Default: no
Environment: DRI_PRIME=pci-0000_01_00_0
The DRI_PRIME variable is never set by default and it’s assumed to be at 0 (so main integrated GPU in most cases) if nothing else sets it.
In the case of Nvidia proprietary drivers, the tool is smart enough to set the appropriate Nvidia variables to achieve the same result:
$ switcherooctl list
Device: 0
Name: Intel Corporation Raptor Lake-P [Iris Xe Graphics]
Default: yes
Environment: DRI_PRIME=pci-0000_00_02_0
Device: 1
Name: NVIDIA Corporation AD104GLM [RTX 3500 Ada Generation Laptop GPU]
Default: no
Environment: __GLX_VENDOR_LIBRARY_NAME=nvidia __NV_PRIME_RENDER_OFFLOAD=1 __VK_LAYER_NV_optimus=NVIDIA_only
Think of switcherooctl as a replacement for setting up variables. For example, if your system has 4 GPUs and you want to target the 4th GPU, these commands are equivalent:
$ switcherooctl launch -g 3 <command>
$ DRI_PRIME=3 <command>
$ DRI_PRIME=pci-0000_03_00_0 <command>
Selecting the GPU to use with environment variables
OpenGL context
OpenGL came in before this multiple GPU – multiple GPU vendor thing existed, so by default, the first used GPU is the one used to run OpenGL applications in the main display and leave the second GPU off:
$ glxinfo -B | grep string
OpenGL vendor string: Intel
OpenGL renderer string: Mesa Intel(R) Graphics (RPL-P)
OpenGL core profile version string: 4.6 (Core Profile) Mesa 24.0.8
OpenGL core profile shading language version string: 4.60
OpenGL version string: 4.6 (Compatibility Profile) Mesa 24.0.8
OpenGL shading language version string: 4.60
OpenGL ES profile version string: OpenGL ES 3.2 Mesa 24.0.8
OpenGL ES profile shading language version string: OpenGL ES GLSL ES 3.20
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
suspended
In the case of the Intel + Nvidia proprietary drivers, we can use the Nvidia variables consumed by the proprietary driver to select the GPU and let the system power on the extra GPU:
$ __NV_PRIME_RENDER_OFFLOAD=1 __GLX_VENDOR_LIBRARY_NAME=nvidia glxinfo -B | grep string
OpenGL vendor string: NVIDIA Corporation
OpenGL renderer string: NVIDIA RTX 3500 Ada Generation Laptop GPU/PCIe/SSE2
OpenGL core profile version string: 4.6.0 NVIDIA 555.42.02
OpenGL core profile shading language version string: 4.60 NVIDIA
OpenGL version string: 4.6.0 NVIDIA 555.42.02
OpenGL shading language version string: 4.60 NVIDIA
OpenGL ES profile version string: OpenGL ES 3.2 NVIDIA 555.42.02
OpenGL ES profile shading language version string: OpenGL ES GLSL ES 3.20
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
active
If we are using open source drivers for both Intel + Nvidia (Nouveau), we can use the Mesa DRI variables to select the GPU:
$ DRI_PRIME=1 glxinfo -B | grep string
OpenGL vendor string: Mesa
OpenGL renderer string: NV194
OpenGL core profile version string: 4.3 (Core Profile) Mesa 24.0.8
OpenGL core profile shading language version string: 4.30
OpenGL version string: 4.3 (Compatibility Profile) Mesa 24.0.8
OpenGL shading language version string: 4.30
OpenGL ES profile version string: OpenGL ES 3.2 Mesa 24.0.8
OpenGL ES profile shading language version string: OpenGL ES GLSL ES 3.20
We can now use both ways of checking the power state of the GPUs via the PCI devices or with VGA Switcheroo:
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
active
$ sudo cat /sys/kernel/debug/vgaswitcheroo/switch
0:IGD:+:Pwr:0000:00:02.0
1:DIS-Audio: :DynOff:0000:01:00.1
2:DIS: :DynPwr:0000:01:00.0
VA-API (Video Acceleration API) context
$ vainfo | grep version
libva info: VA-API version 1.21.0
libva info: Trying to open /usr/lib64/dri/iHD_drv_video.so
libva info: Found init function __vaDriverInit_1_21
libva info: va_openDriver() returns 0
vainfo: VA-API version: 1.21 (libva 2.21.0)
vainfo: Driver version: Intel iHD driver for Intel(R) Gen Graphics - 24.2.3 (Full Feature Build)
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
suspended
VA-API has its own set of variables for selecting which driver to use in the case of Intel + Nvidia proprietary drivers:
$ LIBVA_DRIVER_NAME=nvidia vainfo | grep version
libva info: VA-API version 1.21.0
libva info: User environment variable requested driver 'nvidia'
libva info: Trying to open /usr/lib64/dri/nvidia_drv_video.so
libva info: Found init function __vaDriverInit_1_0
libva info: va_openDriver() returns 0
vainfo: VA-API version: 1.21 (libva 2.21.0)
vainfo: Driver version: VA-API NVDEC driver [direct backend]
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
active
Again, with the open source stack, also the DRI variable or switcherooctl are required:
$ DRI_PRIME=1 LIBVA_DRIVER_NAME=nouveau vainfo | grep version
libva info: VA-API version 1.21.0
libva info: User environment variable requested driver 'nouveau'
libva info: Trying to open /usr/lib64/dri/nouveau_drv_video.so
libva info: Found init function __vaDriverInit_1_21
libva info: va_openDriver() returns 0
vainfo: VA-API version: 1.21 (libva 2.21.0)
vainfo: Driver version: Mesa Gallium driver 24.0.8 for NV194
$ cat /sys/bus/pci/devices/0000:{00:02.0,01:00.0}/power/runtime_status
active
active
VDPAU context
VDPAU is pretty much dead, there is no support for Optimus/Prime laptops and no support for Wayland.
Vulkan or EGL context
Vulkan and EGL were thought with this use case in mind and the selection of the GPU to use ties into the extensions, so usually the correct one is already considered by the program using the appropriate API. The program can query a particular extension to get an ordered list of GPUs or with some other mechanism. This is usually performed by the program itself, so there is not really a way to “force” one specific GPU.
For example, vkcube allows us to select the GPU:
$ vkcube --gpu_number 0 --c 20
Selected GPU 0: Intel(R) Graphics (RPL-P), type: IntegratedGpu
$ vkcube --gpu_number 1 --c 20
Selected GPU 1: NVIDIA RTX 3500 Ada Generation Laptop GPU, type: DiscreteGpu
Contrary to the OpenGL context, you can check with the following commands that there is always a list of GPUs to use and never a single GPU information:
$ eglinfo -B
$ __NV_PRIME_RENDER_OFFLOAD=1 eglinfo -B
$ vulkaninfo --summary
There are some variables or programs that can be used to influence the extensions used for querying the GPUs, but it’s not really a supported path. The application decides based on the information provided by the drivers and some predefined criteria.
Forcing the usage of X on a specific GPU in a Wayland context
Everything described so far is applied as well to Wayland. On top of that, Xwayland is started whenever an application that does not support Wayland yet is started in a Wayland desktop.
If you want to force the use of Xwayland for a program that supports both Wayland and X, then you just need to set an additional variable.
For example, depending on the context (DRI, Nvidia, etc), these are all equivalent:
$ XDG_SESSION_TYPE=X11 __NV_PRIME_RENDER_OFFLOAD=1 __GLX_VENDOR_LIBRARY_NAME=nvidia glxgears
$ XDG_SESSION_TYPE=X11 DRI_PRIME=1 glxgears
$ XDG_SESSION_TYPE=X11 switcherooctl launch -g 1 glxgears

Recent Comments